
08 | 调用栈:为什么JavaScript代码会出现栈溢出?
在上篇文章中,我们讲到了,当一段代码被执行时,JavaScript 引擎先会对其进行编译,并创建执行上下文。但是并没有明确说明到底什么样的代码才算符合规范。
那么接下来我们就来明确下,哪些情况下代码才算是“一段”代码,才会在执行之前就进行编译并创建执行上下文。一般说来,有这么三种情况:
当 JavaScript 执行全局代码的时候,会编译全局代码并创建全局执行上下文,而且在整个页面的生存周期内,全局执行上下文只有一份。
当调用一个函数的时候,函数体内的代码会被编译,并创建函数执行上下文,一般情况下,函数执行结束之后,创建的函数执行上下文会被销毁。
当使用 eval 函数的时候,eval 的代码也会被编译,并创建执行上下文。
好了,又进一步理解了执行上下文,那本节我们就在这基础之上继续深入,一起聊聊调用栈。学习调用栈至少有以下三点好处:
可以帮助你了解 JavaScript 引擎背后的工作原理;
让你有调试 JavaScript 代码的能力;
帮助你搞定面试,因为面试过程中,调用栈也是出境率非常高的题目。
比如你在写 JavaScript 代码的时候,有时候可能会遇到栈溢出的错误,如下图所示:
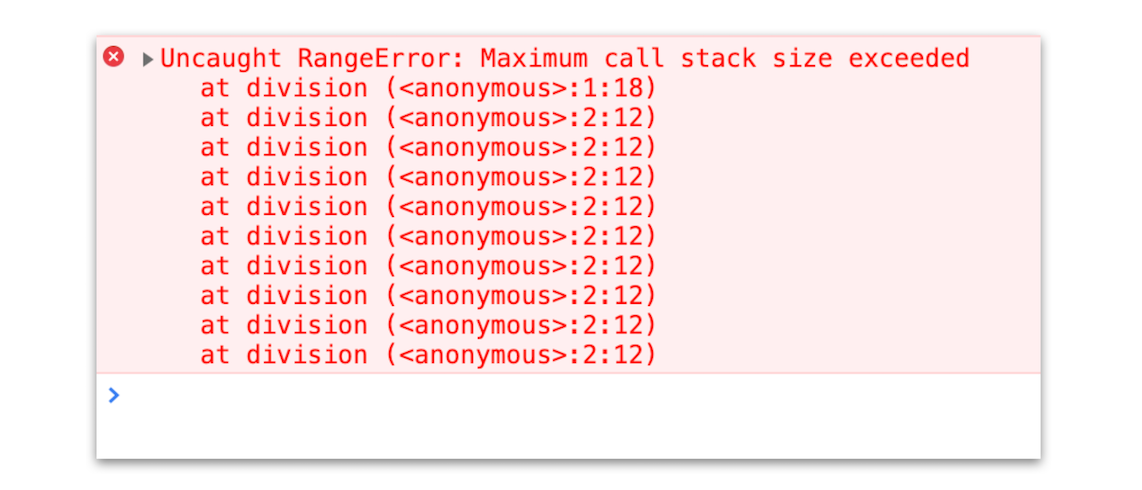
那为什么会出现这种错误呢?这就涉及到了调用栈的内容。你应该知道 JavaScript 中有很多函数,经常会出现在一个函数中调用另外一个函数的情况,调用栈就是用来管理函数调用关系的一种数据结构。因此要讲清楚调用栈,你还要先弄明白函数调用和栈结构。
什么是函数调用
函数调用就是运行一个函数,具体使用方式是使用函数名称跟着一对小括号。下面我们看个简单的示例代码:
var a = 2
function add(){
var b = 10
return a+b
}
add()
这段代码很简单,先是创建了一个 add 函数,接着在代码的最下面又调用了该函数。
那么下面我们就利用这段简单的代码来解释下函数调用的过程。
在执行到函数 add() 之前,JavaScript 引擎会为上面这段代码创建全局执行上下文,包含了声明的函数和变量,你可以参考下图:
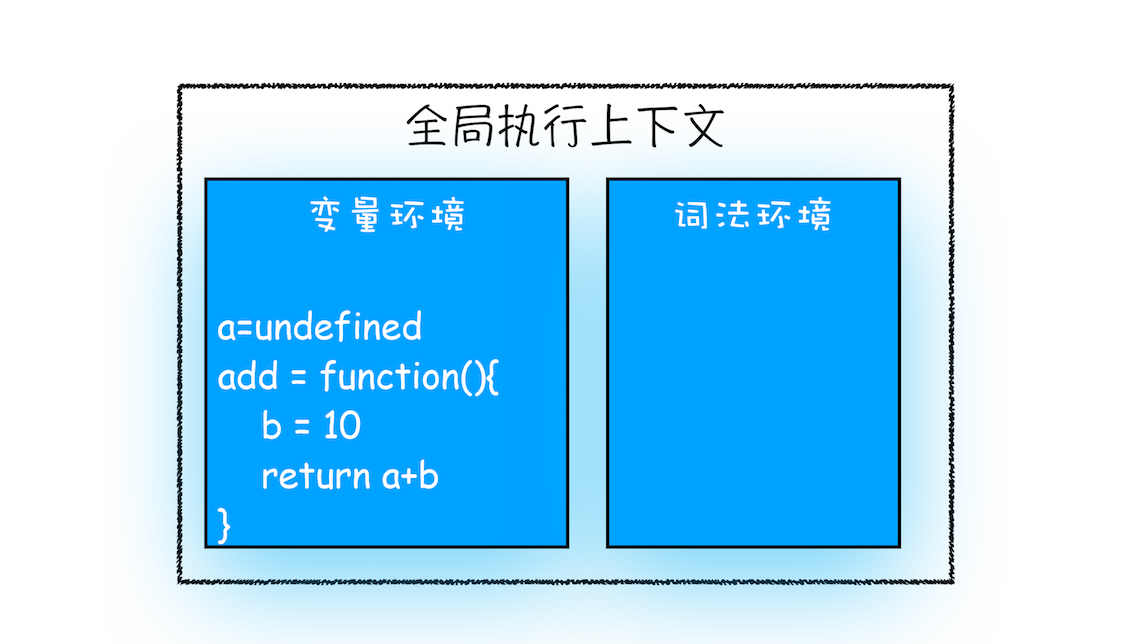
从图中可以看出,代码中全局变量和函数都保存在全局上下文的变量环境中。
执行上下文准备好之后,便开始执行全局代码,当执行到 add 这儿时,JavaScript 判断这是一个函数调用,那么将执行以下操作:
首先,从全局执行上下文中,取出 add 函数代码。
其次,对 add 函数的这段代码进行编译,并创建该函数的执行上下文和可执行代码。
最后,执行代码,输出结果。
完整流程你可以参考下图:
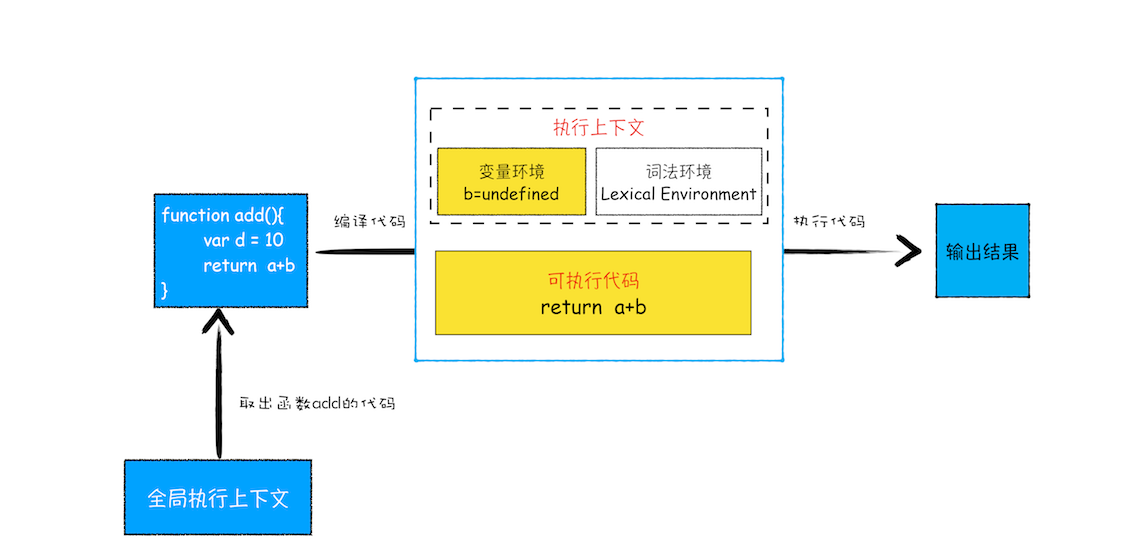
就这样,当执行到 add 函数的时候,我们就有了两个执行上下文了——全局执行上下文和 add 函数的执行上下文。
也就是说在执行 JavaScript 时,可能会存在多个执行上下文,那么 JavaScript 引擎是如何管理这些执行上下文的呢?
答案是通过一种叫栈的数据结构来管理的。那什么是栈呢?它又是如何管理这些执行上下文呢?
什么是栈
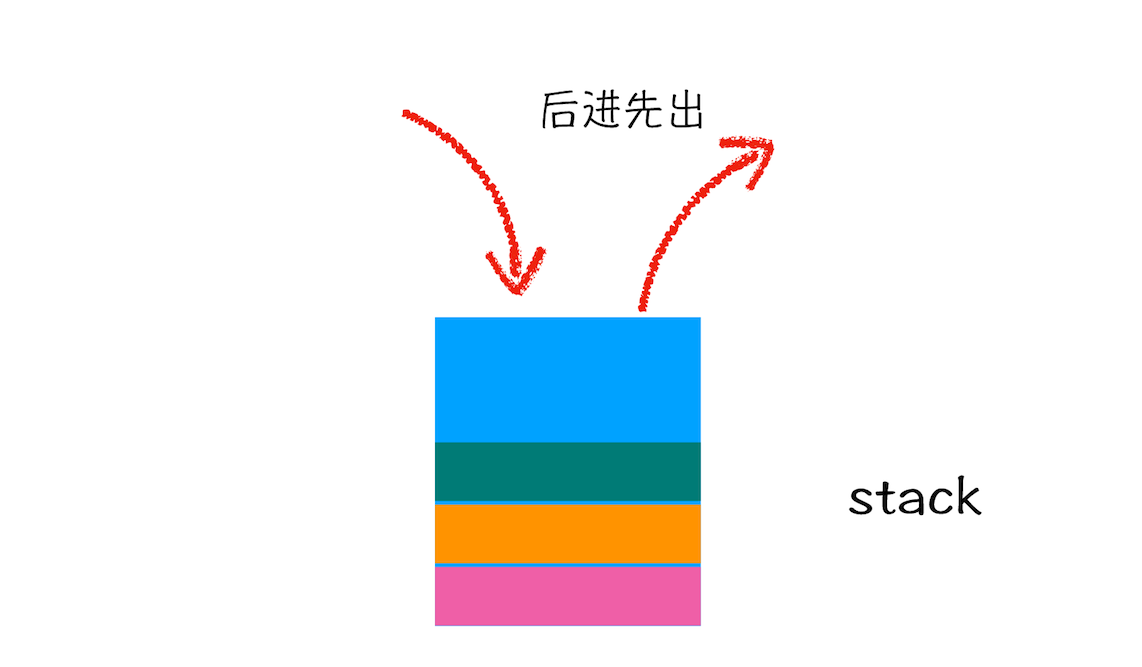
关于栈,你可以结合这么一个贴切的例子来理解,一条单车道的单行线,一端被堵住了,而另一端入口处没有任何提示信息,堵住之后就只能后进去的车子先出来,这时这个堵住的单行线就可以被看作是一个栈容器,车子开进单行线的操作叫做入栈,车子倒出去的操作叫做出栈。
在车流量较大的场景中,就会发生反复的入栈、栈满、出栈、空栈和再次入栈,一直循环。
所以,栈就是类似于一端被堵住的单行线,车子类似于栈中的元素,栈中的元素满足后进先出的特点。你可以参看下图:
什么是 JavaScript 的调用栈
JavaScript 引擎正是利用栈的这种结构来管理执行上下文的。在执行上下文创建好后,JavaScript 引擎会将执行上下文压入栈中,通常把这种用来管理执行上下文的栈称为执行上下文栈,又称调用栈。
为便于你更好地理解调用栈,下面我们再来看段稍微复杂点的示例代码:
var a = 2
function add(b,c){
return b+c
}
function addAll(b,c){
var d = 10
result = add(b,c)
return a+result+d
}
addAll(3,6)
在上面这段代码中,你可以看到它是在 addAll 函数中调用了 add 函数,那在整个代码的执行过程中,调用栈是怎么变化的呢?
下面我们就一步步地分析在代码的执行过程中,调用栈的状态变化情况。
第一步,创建全局上下文,并将其压入栈底。如下图所示:
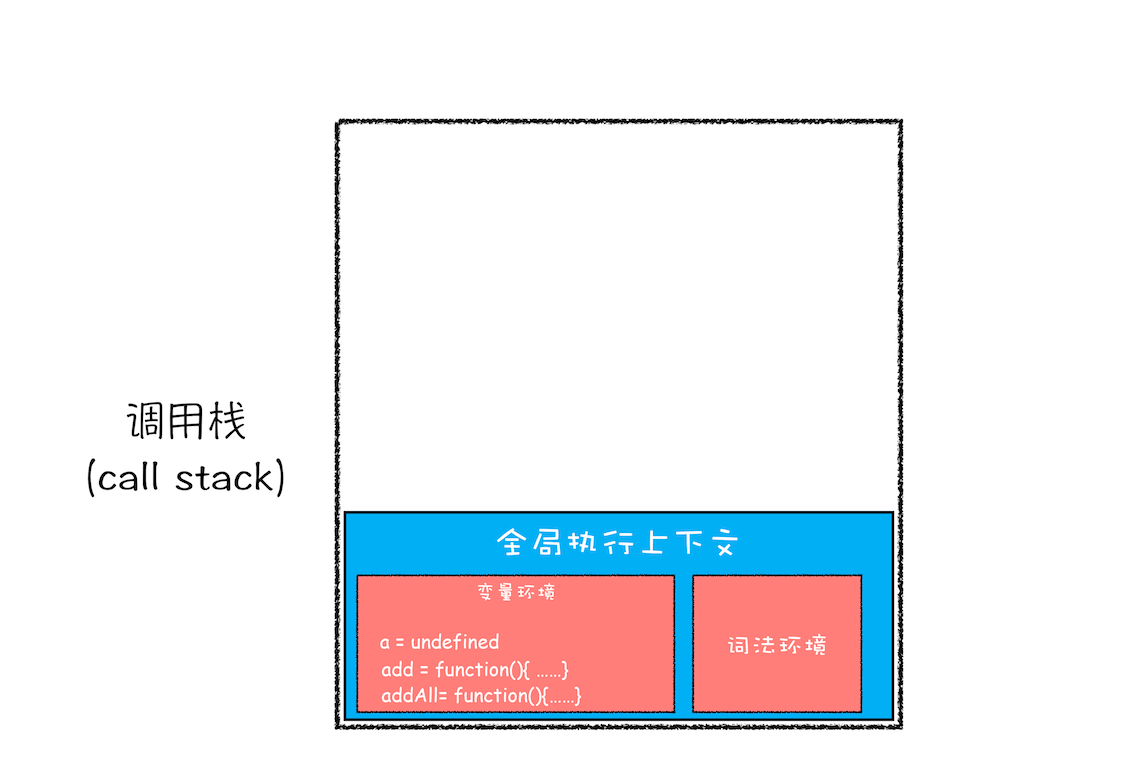
从图中你也可以看出,变量 a、函数 add 和 addAll 都保存到了全局上下文的变量环境对象中。
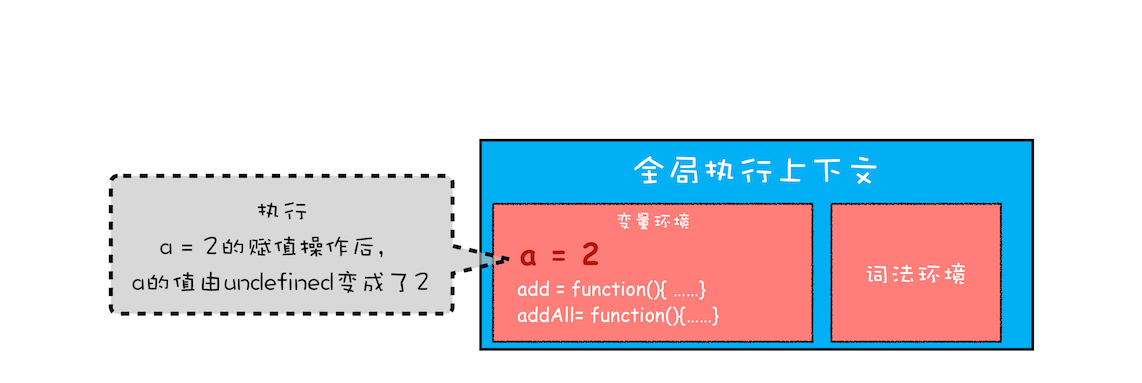
全局执行上下文压入到调用栈后,JavaScript 引擎便开始执行全局代码了。首先会执行 a=2 的赋值操作,执行该语句会将全局上下文变量环境中 a 的值设置为 2。设置后的全局上下文的状态如下图所示:
接下来,第二步是调用 addAll 函数。当调用该函数时,JavaScript 引擎会编译该函数,并为其创建一个执行上下文,最后还将该函数的执行上下文压入栈中,如下图所示:
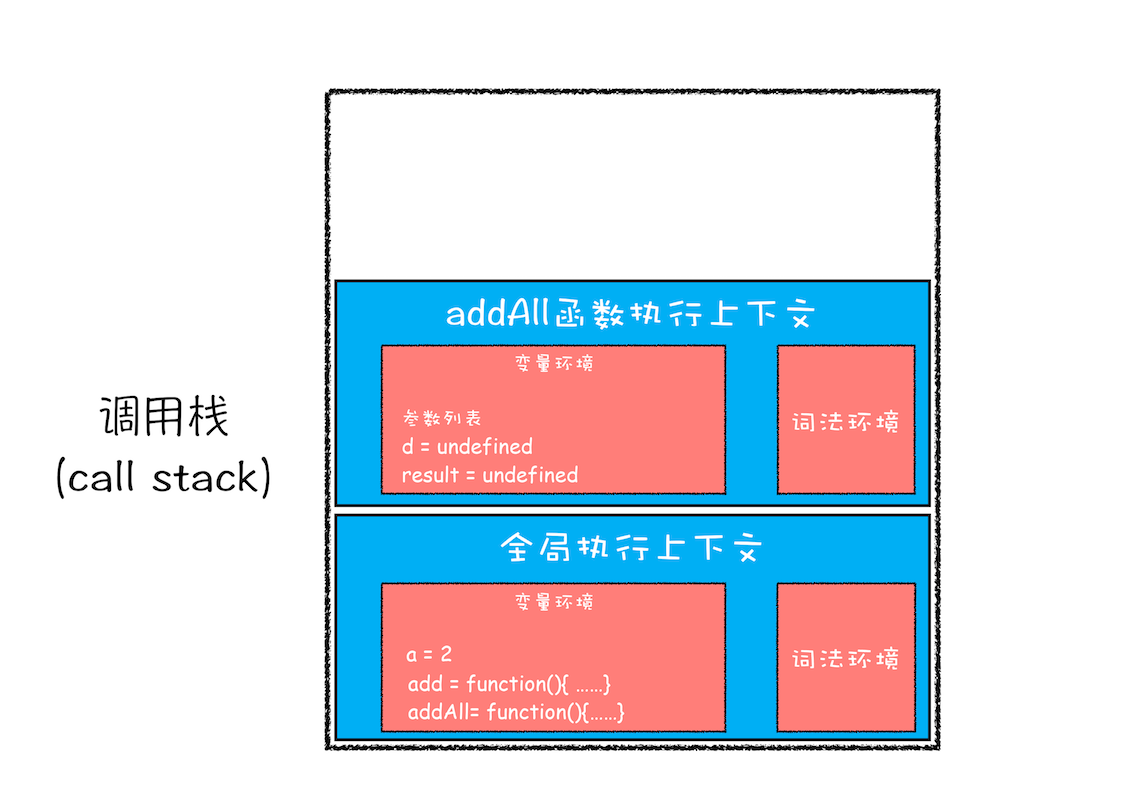
addAll 函数的执行上下文创建好之后,便进入了函数代码的执行阶段了,这里先执行的是 d=10 的赋值操作,执行语句会将 addAll 函数执行上下文中的 d 由 undefined 变成了 10。
然后接着往下执行,第三步,当执行到 add 函数调用语句时,同样会为其创建执行上下文,并将其压入调用栈,如下图所示:
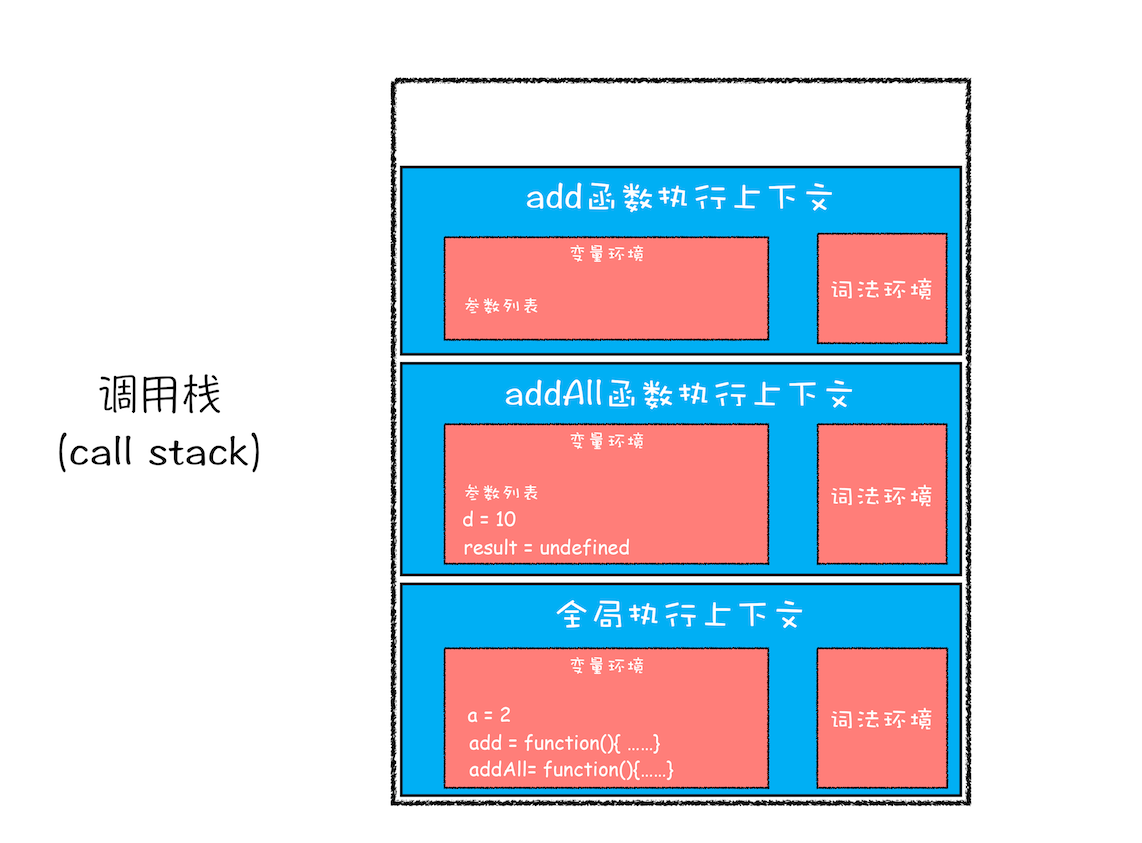
当 add 函数返回时,该函数的执行上下文就会从栈顶弹出,并将 result 的值设置为 add 函数的返回值,也就是 9。如下图所示:
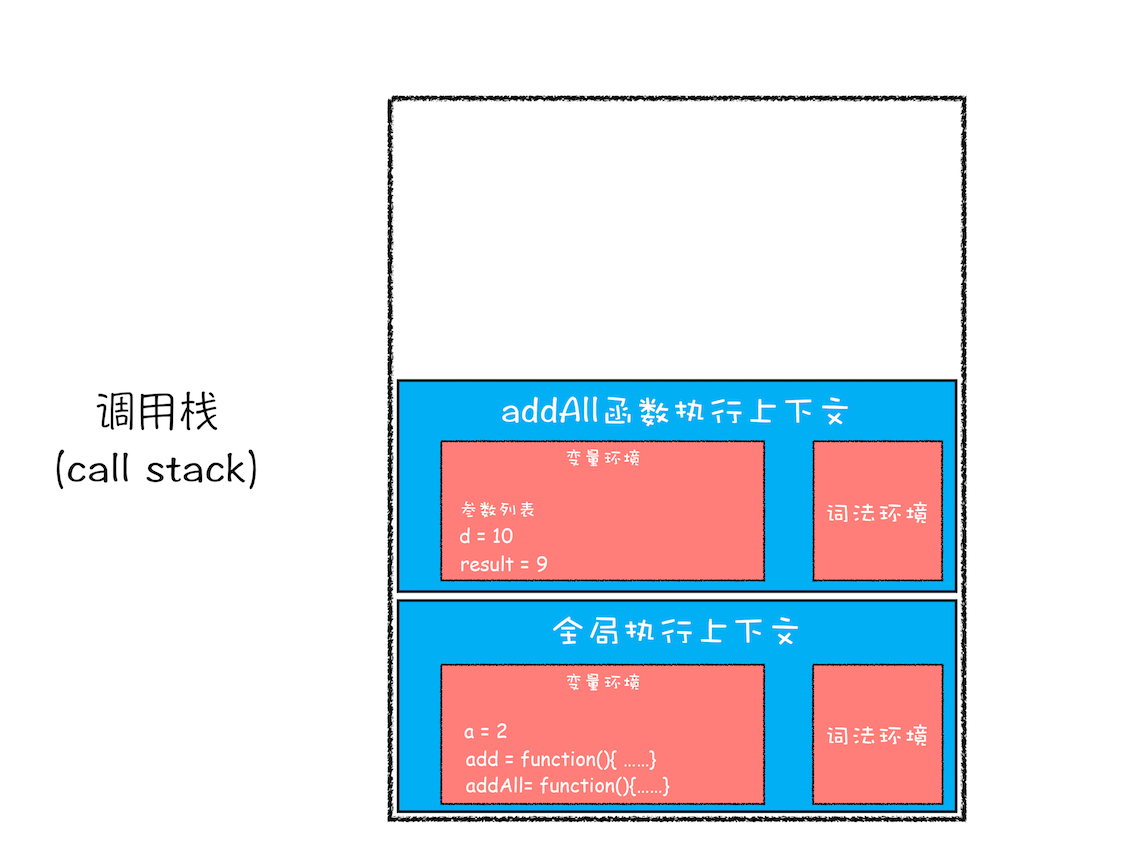
紧接着 addAll 执行最后一个相加操作后并返回,addAll 的执行上下文也会从栈顶部弹出,此时调用栈中就只剩下全局上下文了。最终如下图所示:
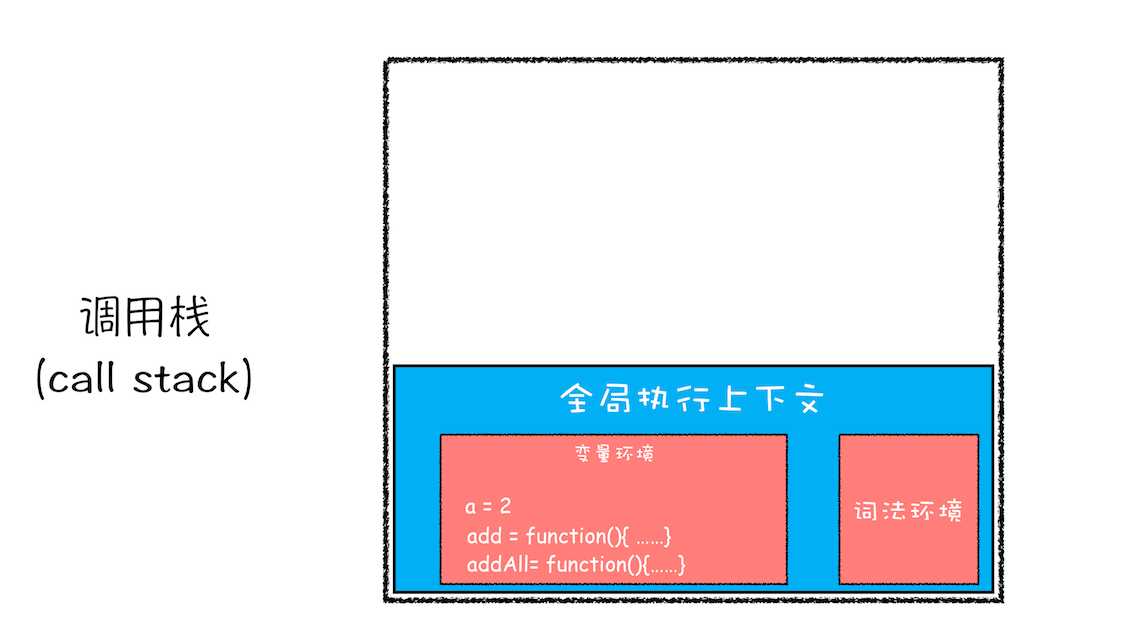
至此,整个 JavaScript 流程执行结束了。
好了,现在你应该知道了调用栈是 JavaScript 引擎追踪函数执行的一个机制,当一次有多个函数被调用时,通过调用栈就能够追踪到哪个函数正在被执行以及各函数之间的调用关系。
在开发中,如何利用好调用栈
鉴于调用栈的重要性和实用性,那么接下来我们就一起来看看在实际工作中,应该如何查看和利用好调用栈。
1. 如何利用浏览器查看调用栈的信息
当你执行一段复杂的代码时,你可能很难从代码文件中分析其调用关系,这时候你可以在你想要查看的函数中加入断点,然后当执行到该函数时,就可以查看该函数的调用栈了。
这么说可能有点抽象,这里我们拿上面的那段代码做个演示,你可以打开“开发者工具”,点击“Source”标签,选择 JavaScript 代码的页面,然后在第 3 行加上断点,并刷新页面。你可以看到执行到 add 函数时,执行流程就暂停了,这时可以通过右边“call stack”来查看当前的调用栈的情况,如下图:
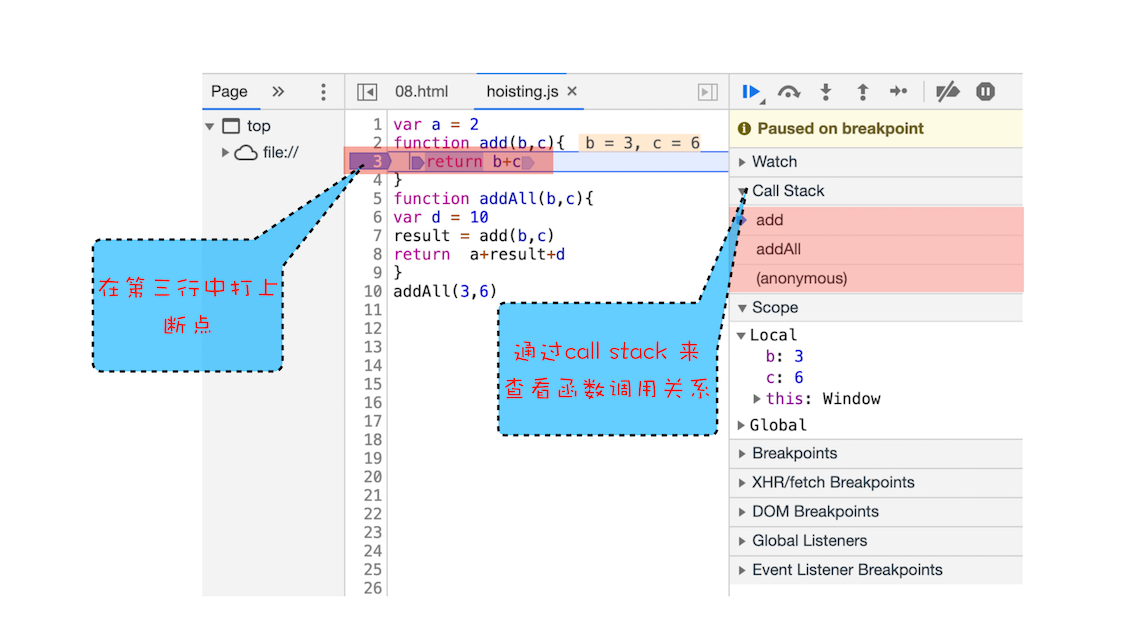
从图中可以看出,右边的“call stack”下面显示出来了函数的调用关系:栈的最底部是 anonymous,也就是全局的函数入口;中间是 addAll 函数;顶部是 add 函数。这就清晰地反映了函数的调用关系,所以在分析复杂结构代码,或者检查 Bug 时,调用栈都是非常有用的。
除了通过断点来查看调用栈,你还可以使用 console.trace() 来输出当前的函数调用关系,比如在示例代码中的 add 函数里面加上了 console.trace(),你就可以看到控制台输出的结果,如下图:

2. 栈溢出(Stack Overflow)
现在你知道了调用栈是一种用来管理执行上下文的数据结构,符合后进先出的规则。不过还有一点你要注意,调用栈是有大小的,当入栈的执行上下文超过一定数目,JavaScript 引擎就会报错,我们把这种错误叫做栈溢出。
特别是在你写递归代码的时候,就很容易出现栈溢出的情况。比如下面这段代码:
function division(a,b){
return division(a,b)
}
console.log(division(1,2))
当执行时,就会抛出栈溢出错误,如下图:

从上图你可以看到,抛出的错误信息为:超过了最大栈调用大小(Maximum call stack size exceeded)。
那为什么会出现这个问题呢?这是因为当 JavaScript 引擎开始执行这段代码时,它首先调用函数 division,并创建执行上下文,压入栈中;然而,这个函数是递归的,并且没有任何终止条件,所以它会一直创建新的函数执行上下文,并反复将其压入栈中,但栈是有容量限制的,超过最大数量后就会出现栈溢出的错误。
理解了栈溢出原因后,你就可以使用一些方法来避免或者解决栈溢出的问题,比如把递归调用的形式改造成其他形式,或者使用加入定时器的方法来把当前任务拆分为其他很多小任务。
总结
好了,今天的内容就讲到这里,下面来总结下今天的内容。
每调用一个函数,JavaScript 引擎会为其创建执行上下文,并把该执行上下文压入调用栈,然后 JavaScript 引擎开始执行函数代码。
如果在一个函数 A 中调用了另外一个函数 B,那么 JavaScript 引擎会为 B 函数创建执行上下文,并将 B 函数的执行上下文压入栈顶。
当前函数执行完毕后,JavaScript 引擎会将该函数的执行上下文弹出栈。
当分配的调用栈空间被占满时,会引发“堆栈溢出”问题。
栈是一种非常重要的数据结构,不光应用在 JavaScript 语言中,其他的编程语言,如 C/C++、Java、Python 等语言,在执行过程中也都使用了栈来管理函数之间的调用关系。所以栈是非常基础且重要的知识点,你必须得掌握。
思考时间
最后,我给你留个思考题,你可以看下面这段代码:
function runStack (n) {
if (n === 0) return 100;
return runStack( n- 2);
}
runStack(50000)
这是一段递归代码,可以通过传入参数 n,让代码递归执行 n 次,也就意味着调用栈的深度能达到 n,当输入一个较大的数时,比如 50000,就会出现栈溢出的问题,那么你能优化下这段代码,以解决栈溢出的问题吗?